Towards a National Data Service
- Kenton McHenry
The National Data Service Consortium (NDSC) aims to enhance scientific reproduciblity in the Information Age by implementing interfaces, protocols, and standards within data relevant cyberinfrastructure tools/services towards allowing for an overall infrastructure enabling scientists to more easily search for, publish, link, and overall reuse digital data. Specifically, NDSC has as its mission:
One might think of this in terms of the modern internet, which had its roots in the ARPANET effort ...
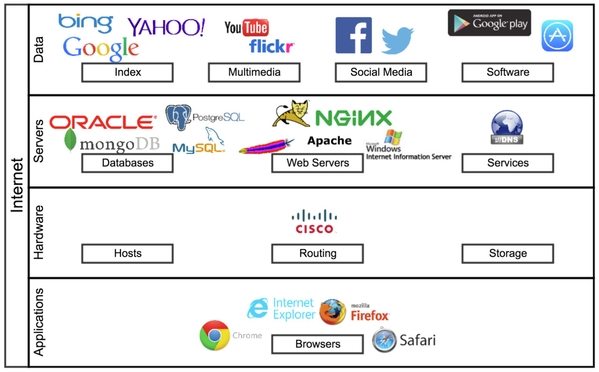
... taking into account additional components addressing "Big Data" challenges within the internet, a sort of DATANET:
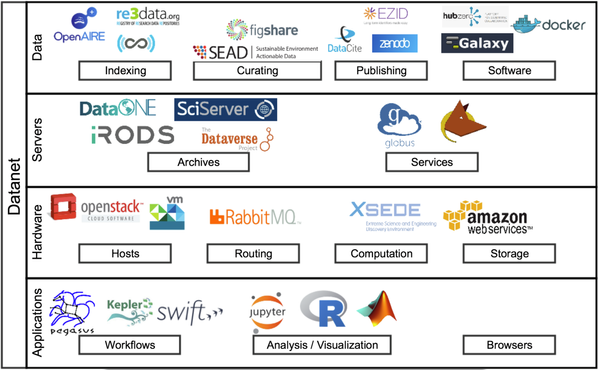
The above is illustrative and not a comprehensive list of services. There are a variety of components being actively explored and developed, some building on top of others, some not, some interacting with others, some not. In essence, just like with every Internet component there are a variety of options for each Datanet component. Unlike the internet components, however, these selections matter - they effect the user and limit what other components might be utilized/deployed.
For example, in the context of internet technologies, consider a web admin deploying a web server: the admin will pick one server over another for one reason or another, e.g. the open source Apache HTTP server, NGINX, or the commercial Microsoft IIS server. IDEALLY this decision will not affect users, because their browser, also a choice to be made this time on the users end, will work either way. This is the case because web servers and browsers implement similar protocols/standards (e.g. HTTP, HTML, ...).
In collaboration with groups like the Research Data Alliance (RDA) we aim to also achieve this standardization among the actively developed data components being constructed today, allowing them to be more readily put together, and allowing scientists as well as others to more easily:
- publish data, link data to papers, cite data, get credit for your data
- preserve data for longer periods of time
- efficiently and reliably move large amounts of data and/or large numbers of files
- share data collections over the web
- set data access permissions
- search for data
- reuse data
- find desired data and be able to access that data
- run custom tools/software on data, near the data
- run compute intensive analysis on data
- run analysis on large collections of data
- run analysis across any available resources
- utilize an extensible suite of reusable data analysis/manipulation tools
- preserve, share, and find software/tools associated with the data
- publish software, cite software, get credit for your software
- create and share workflows over data
- ask novel questions spanning all available data
Overall this will accelerate and enable novel science, allowing stories such as these to become the norm rather than the exception:
- Scientists have pinned down a molecular process in the brain that helps to trigger schizophrenia by analyzing data from about 29,000 schizophrenia cases, 36,000 controls and 700 post mortem brains. The information was drawn from dozens of studies performed in 22 countries. The authors stressed that their findings, which combine basic science with large-scale analysis of genetic studies, depended on an unusual level of cooperation among experts in genetics, molecular biology, developmental neurobiology and immunology. "This could not have been done five years ago".
- Researchers discover that rising atmospheric CO2 is resulting in less nutritious food, requiring 17 years of work across the literature of several disciplines.
... and in terms of the general public and broader impact, perhaps seeding a new kind of internet all can take advantage of:
- A child might ask their Apple TV or Amazon Echo the question, "What is the weather going to be like in the afternoon... 1000 years from now?". This will not result in an answer today, but theoretically could with several of the actively developed data components and interoperability between them. For example, ecological models such as ED, SIPNET, or DALEC within workflow engines such as PEcAn could pull data from Ameriflux, NARR, BETYdb, DataONE, and NEON, transfer data via Globus, convert data to model input formats via BrownDog, run models on XSEDE resources, and returns a specific result such as temperature/forecast estimate (likely several results from several models). The result can further include additional information such as "if you want to learn more" which links to summarized versions of publications for the utilized models and datasets with DOIs to published papers or datasets in Zenodo or SEAD or executable versions of the the tools themselves (possibly simplified) within HUBzero or Jupyter lab notebooks.